Most of the time when we analyze performance of different programs, we use
Big O Notation and run performance tests for a single input size N, which measures execution time.
Both of these methods have disadvantages.
Big O Notation is theoretical (has no code verification).
Time based performance tests are not very reliable (it's hard to make assertions on them) and don't show the actual asymptotic function behind the programs.
Here I present a slightly different approach, which is a combination of those 2 techniques.
It uses explicit instruction counting, samples programs for different input sizes and tries to guess asymptotic function behind them.
It also plots the result as a chart using HTML and
Google Visualization JavaScript Library.
Note that it's more of a toy for visualization than something one could use in the industry for real world projects.
First we start by implementing an example program (
Binary Counter), which we want to measure. It'll extend a base class Benchmark, which looks like this (full source code is available on github:
https://github.com/rafalrusin/abench):
public abstract class Benchmark {
private int instructionCount = 0;
protected void incrementInstructionCount() {
instructionCount++;
}
public void resetInstructionCount() {
instructionCount = 0;
}
public int getInstructionCount() {
return instructionCount;
}
protected abstract Object run(int n);
}
It has abstact method "run", which takes input size as argument. This will be provided by the benchmark framework for different executions.
Binary Counter implementation looks like this:
public class BinaryCounter extends Benchmark {
@Override
protected Object run(int n) {
int[] counter = new int[64];
for (int i = 0; i < n; i++) {
int p = 0;
while (counter[p] == 1) {
counter[p++] = 0;
incrementInstructionCount();
}
counter[p] = 1;
incrementInstructionCount();
}
return counter;
}
}
It is a 64 bit binary counter, which starts from 0 and increments values N times by one. Theoretically it should run in O(n) time. We'll verify that.
We need to run it through the framework using following code:
public class Main {
public static void main(String[] args) {
BenchmarkRunner benchmarkRunner = new BenchmarkRunner();
benchmarkRunner.addFormatter(new TextResultFormatter(new PrintWriter(System.out)));
benchmarkRunner.addFormatter(new HtmlResultFormatter(new File("out")));
for (Benchmark benchmark : new Benchmark[]{
new BinaryCounter(),
...
) {
benchmarkRunner.run(benchmark, 1);
}
}
Here's the chart generated for Binary Counter along with guessed function behind it:
In this case the guessed function is linear, which is what we expected. For input size of 5.6 millions, the instruction count was 11 million.
The guessing process is an iteration over all samples and optimization of
Mean Squared Error.
It is implemented in BenchmarkRunner class.
You can add more functions by extending Function interface. Here's an example of N log N function:
public class NLogNFunction implements Function {
@Override
public float eval(float x) {
return (float) (Math.log(x) * x);
}
}
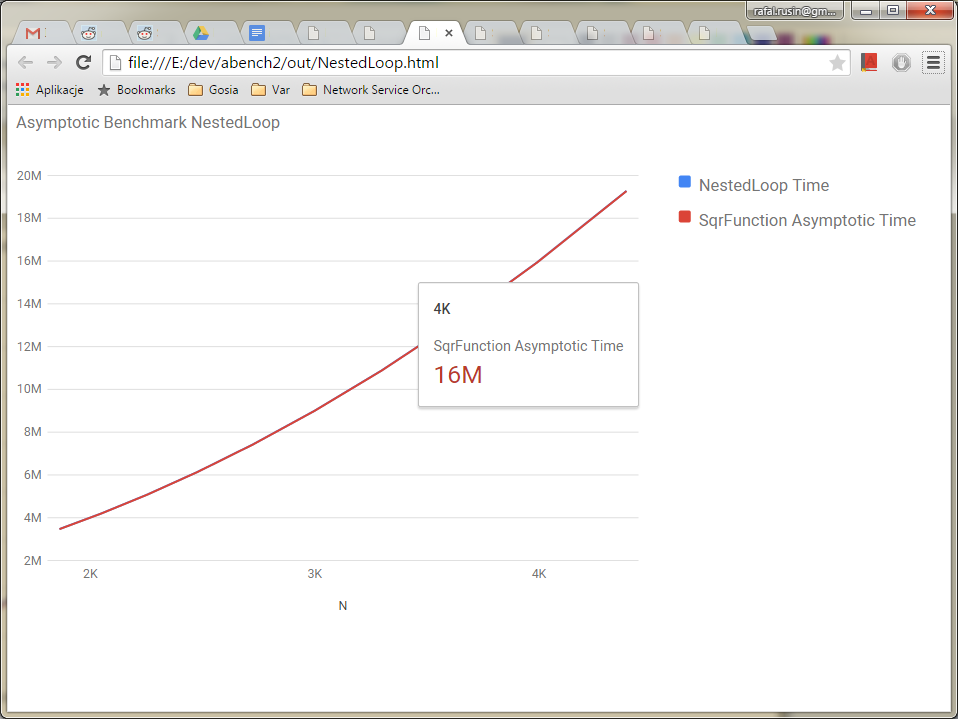
Here's some more benchmarks: MergeSort (expected asymptotic function is N log N) and NestedLoop (N^2).
Implementing reliable performance tests is not a very well solved problem today. I think that the idea of instruction counting is something one can try to use in real world projects. It can be used for testing performance of isolated chunks of code, within unit tests, and can give predictable results.